How the CUDA Runtime Works
Suppose Process A launches GPU work through the CUDA Runtime. The runtime creates a separate GPU context for that process, and the scheduler chooses a context and runs kernels. Tasks inside the same context can run concurrently, but tasks in different contexts run one after another.
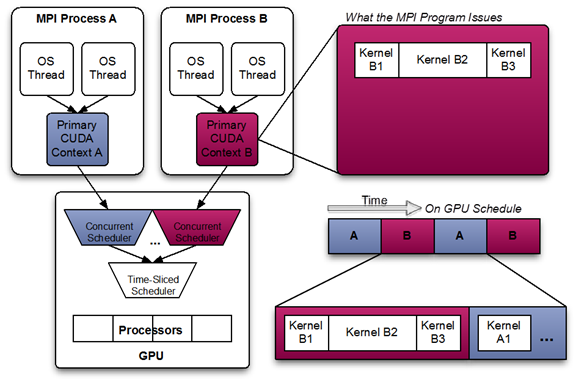
Why MPS is Needed
In multi-process GPU workloads, skipping MPS means every process makes its own context, so kernels queue up per context and utilization drops.
What MPS Does
MPS (Multi-Process Service) creates a single global context that multiple processes share. Each process still calls the CUDA Runtime API the same way, but connects to the MPS server, which intercepts runtime/driver calls, manages the shared context, and lets kernels from different processes run concurrently. GPU-heavy multiprocess workloads get much better utilization this way.
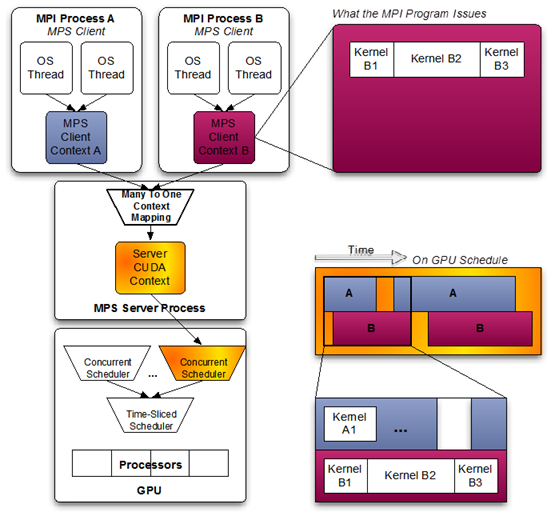
(from the NVIDIA MPS documentation)